Let's Retrieve Documents Locally in the Browser
Patch an OpenAI client with Function LLM in one line of code.

Whether you’re a solopreneur building an intelligent search app; or you’re a series A startup finding product-market fit in enterprise knowledge management; you can be saving 60% or more on your monthly OpenAI bills by generating embeddings on your users’ devices. We’ll show you how you can extract huge margins (and hopefully reach your next funding round) in about 5 minutes with one extra line of code:
Your Current Stack Is Leaving Money On The Table
Text embeddings form the foundation of many AI-powered apps today. They work by turning any arbitrary block of text into a vector of numbers that retains the semantic meaning of the text:
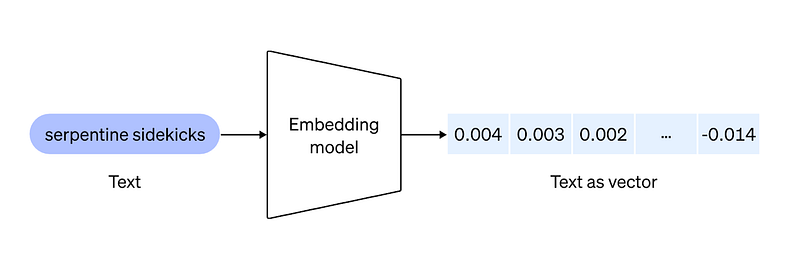
Right now, a lot of developers rely on OpenAI to generate these embeddings, and are charged on a per-token basis. Each token costs a fraction of a cent, but when you multiply that by thousands (or millions) of users, each throwing tons of text at you every month (millions of tokens), you end up with monthly bills in the tens of thousands of dollars or more.
Enter: On-Device Embeddings with Function LLM
It is now feasible to run state-of-the-art text and vision embedding models directly on your users’ devices. To do so, we have created a lightweight library, Function LLM, which patches your OpenAI client to generate embeddings fully locally, both in the browser and on Node.js:
To launch, we’ve partnered up with Nomic, pioneers of the on-device AI movement, and the makers of the popular GPT4All app. Function LLM supports their state-of-the-art Nomic Embed Text v1.5 embedding model, which boasts better performance than OpenAI’s text-embedding-3-small model at similar dimensionality. Try it out:

How Function LLM Works
Function LLM is a nanolibrary (currently 123 lines of code) which patches the OpenAI client to run Nomic’s embedding model on-device. It does so using our platform, Function, which enables developers to run arbitrary AI functions on-device:
Function works by compiling Python functions for most platforms (Android, browser, iOS, macOS, Linux, and Windows) and airdropping the compiled binaries to users’ devices to run locally.
But Why Not Ollama?
In the past few months, there’s been a crop of amazing startups building infrastructure to run large language models (LLM’s) locally. You’ve probably heard of a few of them: Ollama, LMStudio, LocalAI, and others. Looking over their tech, we can’t help but feel like there’s a sizable, underserved gap in what they offer developers.
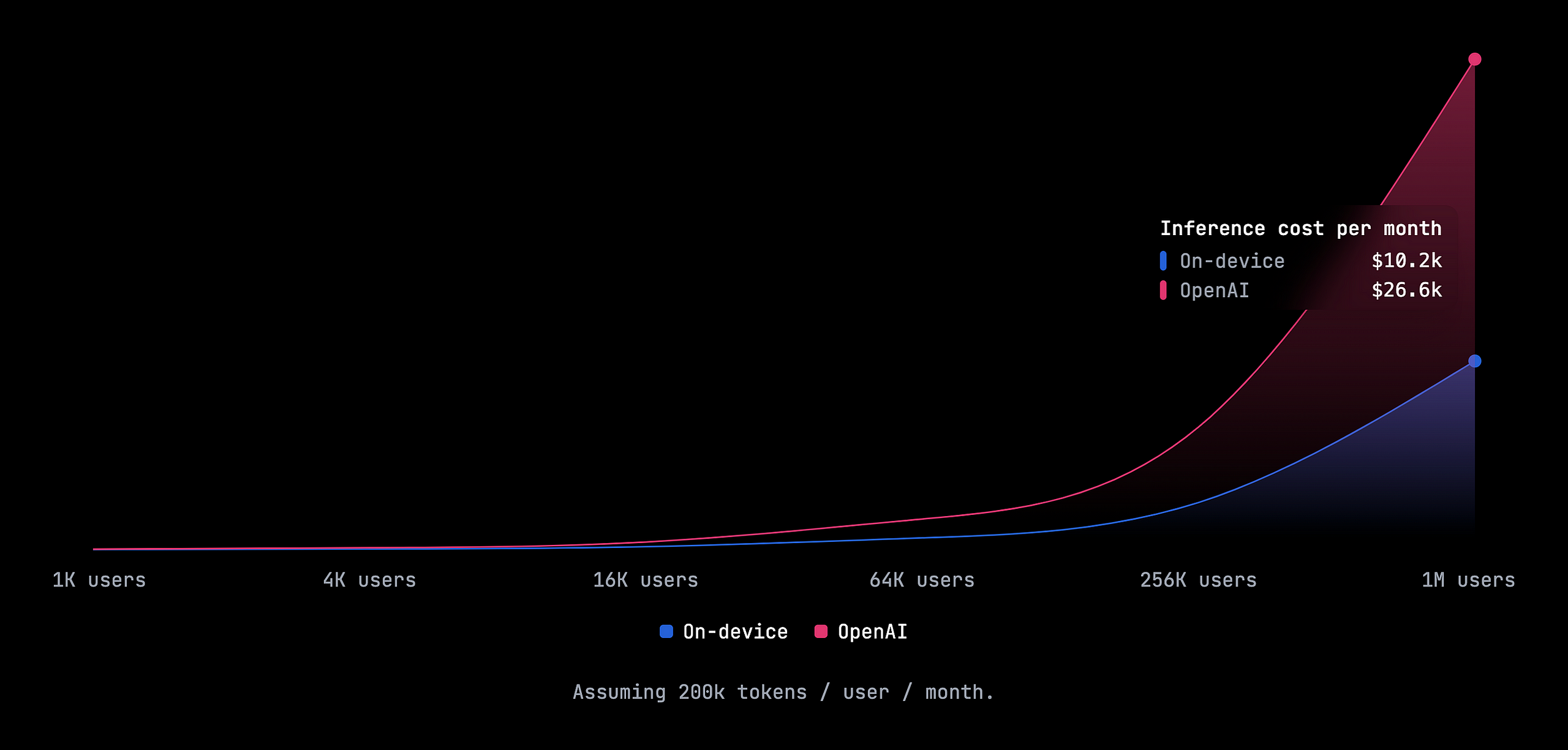
The goal of on-device AI isn’t to go from paying OpenAI to paying AWS for your containerized “local” AI service running in the cloud. It’s quite the opposite: the goal is to push as much of your product’s compute to your users’ devices, thereby sidestepping the need for hosted inference entirely. The benefits in cost and privacy are almost too good to be true, and Apple is perhaps the only major company leading the way on this.
Make It Your Own
One-click deploy the demo to your GitHub account with Vercel, and modify it to fit your needs. Also, make sure to star Function LLM on GitHub!
We’re offering $5 in credits to the first 250 users who sign up to Function.
If you already have an application in production, we’d love to work with you on migrating your app to use on-device embeddings. Reach out to us!